1. Aspects of Data Security
With regard to data-in-transit, the primary risk is in not using a vetted
encryption algorithm. Although this is obvious to information security
professionals, it is not common for others to understand this requirement
when using a public cloud, regardless of whether it is IaaS, PaaS, or
SaaS. It is also important to ensure that a protocol provides
confidentiality as well as integrity (e.g., FTP over SSL [FTPS], Hypertext Transfer Protocol Secure [HTTPS], and Secure Copy Program [SCP])—particularly if the protocol is
used for transferring data across the Internet. Merely encrypting data and
using a non-secured protocol (e.g., “vanilla” or “straight” FTP or HTTP)
can provide confidentiality, but does not ensure the integrity of the data (e.g., with
the use of symmetric streaming ciphers).
Although using encryption to protect data-at-rest might seem obvious, the reality is not that
simple. If you are using an IaaS cloud service (public or private) for
simple storage (e.g., Amazon’s Simple Storage Service or S3), encrypting
data-at-rest is possible—and is strongly suggested. However, encrypting
data-at-rest that a PaaS or SaaS cloud-based application is using (e.g.,
Google Apps, Salesforce.com) as a compensating control is not always
feasible. Data-at-rest used by a cloud-based application is generally not
encrypted, because encryption would prevent indexing or searching of that
data.
Generally speaking, with data-at-rest, the economics of cloud
computing are such that PaaS-based applications and SaaS use a multitenancy architecture. In other words, data, when
processed by a cloud-based application or stored for use by
a cloud-based application, is commingled with other users’ data (i.e., it
is typically stored in a massive data store, such as Google’s BigTable). Although applications are often designed
with features such as data tagging to prevent
unauthorized access to commingled data, unauthorized access is still
possible through some exploit of an application vulnerability (e.g.,
Google’s unauthorized data sharing between users of Documents and
Spreadsheets in March 2009). Although some cloud providers have their
applications reviewed by third parties or verified with third-party
application security tools, data is not on a platform dedicated solely to
one organization.
Although an organization’s data-in-transit might be encrypted during transfer to and
from a cloud provider, and its data-at-rest might be encrypted if using simple storage
(i.e., if it is not associated with a specification application), an
organization’s data is definitely not encrypted if it is processed in the cloud (public or
private). For any application to process data, that data must be
unencrypted. Until June 2009, there was no known method for fully
processing encrypted data. Therefore, unless the data is in the cloud for
only simple storage, the data will be unencrypted during at least part of
its life cycle in the cloud—processing at a minimum.
In June 2009, IBM announced that one of its researchers, working with a
graduate student from Stanford University, had developed a fully homomorphic
encryption scheme which allows data to be processed without
being decrypted. This is a huge advance in cryptography, and it will have a significant positive impact
on cloud computing as soon as it moves into deployment. Earlier work on
fully homomorphic encryption (e.g., 2-DNF) was also conducted at Stanford University, but IBM’s
announcement bettered even that promising work. Although the homomorphic
scheme has broken the theoretical barrier to fully homomorphic encryption,
it required immense computational effort. According to Ronald Rivest (MIT
professor and coinventor of the famous RSA encryption scheme), the steps
to make it practical won't be far behind. Other cryptographic research
efforts are underway to limit the amount of data that would need to be
decrypted for processing in the cloud, such as predicate encryption.
Whether the data an organization has put into the cloud is encrypted
or not, it is useful and might be required (for audit or compliance
purposes) to know exactly where and when the data was specifically located
within the cloud. For example, the data might have been transferred to a
cloud provider, such as Amazon Web Services (AWS), on date
x1 at time
y1 and stored in a bucket on
Amazon’s S3 in example1.s3.amazonaws.com, then
processed on date x2 at time
y2 on an instance being used
by an organization on Amazon’s Elastic Compute Cloud (EC2) in
ec2-67-202-51-223.compute-1.amazonaws.com, then
restored in another bucket,
example2.s3.amazonaws.com, before being brought back
into the organization for storage in an internal data warehouse belonging
to the marketing operations group on date
x3 at time
y3. Following the path of data
(mapping application data flows or data path visualization) is known as
data lineage, and it is important for an auditor’s
assurance (internal, external, and regulatory). However, providing data
lineage to auditors or management is time-consuming, even when the
environment is completely under an organization’s control. Trying to
provide accurate reporting on data lineage for a public cloud service is
really not possible. In the preceding example, on what physical system is
that bucket on example1.s3.amazonaws.com, and
specifically where is (or was) that system located? What was the state of
that physical system then, and how would a customer or auditor verify that
information?
Even if data lineage can be established in a public cloud, for some
customers there is an even more challenging requirement and problem:
proving data provenance—not just proving the integrity of the data,
but the more specific provenance of the data. There is an important
difference between the two terms. Integrity of data
refers to data that has not been changed in an unauthorized manner
or by an unauthorized person. Provenance
means not only that the data has integrity, but also that it
is computationally accurate; that is, the data was accurately calculated.
For example, consider the following financial equation:
- SUM((((2*3)*4)/6)−2) = $2.00
With that equation, the expected answer is $2.00. If the answer were
different, there would be an integrity problem. Of course, the assumption
is that the $2.00 is in U.S. dollars, but the assumption could be
incorrect if a different dollar is used with the following associated
assumptions:
The equation is specific to the Australian, Bahamian, Barbadian,
Belize, Bermudian, Brunei, Canadian, Cayman Islands, Cook Islands,
East Caribbean, Fijian, Guyanese, Hong Kong, Jamaican, Kiribati,
Liberian, Namibian, New Zealand, Samoan, Singapore, Solomon Islands,
Surinamese, New Taiwan, Trinidad and Tobago, Tuvaluan, or Zimbabwean
dollar.
The dollar is meant to be converted from another country’s
dollars into U.S. dollars.
The correct exchange rate is used and the conversion is
calculated correctly and can be proven.
In this example, if the equation satisfies those assumptions, the
equation has integrity but not provenance. There are many real-world examples in which data
integrity is insufficient and data provenance is also required. Financial
and scientific calculations are two obvious examples. How do you prove
data provenance in a cloud computing scenario when you are using shared
resources? Those resources are not under your physical or even logical
control, and you probably have no ability to track the systems used or
their state at the times you used them—even if you know some identifying
information about the systems (e.g., their IP addresses) and the “general”
location (e.g., a country, and not even a specific data center).
A final aspect of data security is
data remanence. “Data remanence is the
residual representation of data that has been in some way nominally erased
or removed. This residue may be due to data being left intact by a nominal
delete operation, or through physical properties of the storage medium.
Data remanence may make inadvertent disclosure of sensitive information
possible, should the storage media be released into an uncontrolled
environment (e.g., thrown in the trash, or given to a third
party).”
The risk posed by data remanence in cloud services is that an
organization’s data can be inadvertently exposed to an unauthorized
party—regardless of which cloud service you are using (SaaS, PaaS, or
IaaS). When using SaaS or PaaS, the risk is almost certainly unintentional or
inadvertent exposure. However, that is not reassuring after an
unauthorized disclosure, and potential customers should question what
third-party tools or reviews are used to help validate the security of the
provider’s applications or platform.
In spite of the increased importance of data security, the attention
that cloud service providers (CSPs) pay to data remanence is strikingly low. Many do not
even mention data remanence in their services. And if the subject of data
security is broached, many CSPs rather glibly refer to compliance with
U.S. Department of Defense (DoD) 5220.22-M (the National Industrial Security Program Operating Manual). We
say “glibly” because it appears that providers (and other information
technology vendors) have not actually read this manual. DoD 5220.22-M
states the two approved methods of data (destruction) security, but does
not provide any specific requirements for how these two methods are to be
achieved, nor does it provide any standards for how these methods are to
be accomplished. Relevant information in DoD 5220.22-M regarding data
remanence in this 141-page manual is limited to three paragraphs:
“8-301. Clearing and Sanitization”
Instructions on clearing, sanitization, and release of
information systems (IS) media shall be issued by the accrediting
Cognizant Security Agency (CSA).
“a. Clearing”
Clearing is the process of eradicating the data on media before
reusing the media in an environment that provides an acceptable
level of protection for the data that was on the media before
clearing. All internal memory, buffer, or other reusable memory
shall be cleared to effectively deny access to previously stored
information.
“b. Sanitization”
Sanitization is the process of removing the data from media before reusing
the media in an environment that does not provide an acceptable
level of protection for the data that was on the media before
sanitizing. IS resources shall be sanitized before they are released
from classified information controls or released for use at a lower
classification level.
For specific information about how data
security should be achieved, providers should refer to the National
Institute of Standards and Technology (NIST) Special Publication, 800-88, “Guidelines for Media
Sanitization.” Although this NIST publication provides guidelines only, and
is officially meant for federal civilian departments and agencies only,
many companies, especially those in regulated industries, voluntarily
adhere to NIST guidelines and standards. In the absence of any other
industry standard for data remanence, adherence to these NIST guidelines
is important.
2. Data Security MitigationIf prospective customers of cloud computing services expect that data
security will serve as compensating controls for possibly weakened
infrastructure security, since part of a customer’s infrastructure
security moves beyond its control and a provider’s infrastructure security
may (for many enterprises) or may not (for small to medium-size
businesses, or SMBs) be less robust than expectations, you will be
disappointed. Although data-in-transit can and should be encrypted, any
use of that data in the cloud, beyond simple storage, requires that it be
decrypted. Therefore, it is almost certain that in the cloud, data will be
unencrypted. And if you are using a PaaS-based application or SaaS,
customer-unencrypted data will also almost certainly be hosted in a
multitenancy environment (in public clouds). Add to that exposure the difficulties in determining the
data’s lineage, data provenance—where necessary—and even many providers’
failure to adequately address such a basic security concern as data remanence, and the risks of data security for customers
are significantly increased.
So, what should you do to mitigate these risks to data security? The
only viable option for mitigation is to ensure that any sensitive or
regulated data is not placed into a public cloud (or that you encrypt data placed into the cloud for simple storage only).
Given the economic considerations of cloud computing today, as well as the
present limits of cryptography, CSPs are not offering robust enough controls around data
security. It may be that those economics change and that providers offer
their current services, as well as a “regulatory cloud environment” (i.e.,
an environment where customers are willing to pay more for enhanced
security controls to properly handle sensitive and regulated data).
Currently, the only viable option for mitigation is to ensure that any
sensitive or regulated data is not put into a public cloud.
3. Provider Data and Its Security
In addition to the security of your own customer data, customers should also be
concerned about what data the provider collects and how the CSP protects
that data. Specifically with regard to your customer data, what metadata does the provider have about your data, how is it
secured, and what access do you, the customer, have to that metadata? As
your volume of data with a particular provider increases, so does the
value of that metadata.
Additionally, your provider collects and must protect a huge amount
of security-related data. For example, at the network level, your provider
should be collecting, monitoring, and protecting firewall, intrusion prevention system (IPS), security incident and event management (SIEM), and router flow data. At the host level your provider should be collecting system
logfiles, and at the application level SaaS providers should be collecting
application log data, including authentication and authorization information.
What data your CSP collects and how it monitors and protects that
data is important to the provider for its own audit purposes . Additionally, this information is
important to both providers and customers in case it is needed for
incident response and any digital forensics required for incident
analysis.
3.1. Storage
For data stored in the cloud (i.e., storage-as-a-service), we are
referring to IaaS and not data associated with an application running
in the cloud on PaaS or SaaS. The same three information security
concerns are associated with this data stored in the cloud (e.g.,
Amazon’s S3) as with data stored elsewhere: confidentiality, integrity,
and availability.
3.1.1. Confidentiality
When it comes to the confidentiality of data stored in a public cloud, you
have two potential concerns. First, what access control exists to
protect the data? Access control consists of both authentication and authorization.CSPs generally use weak authentication mechanisms (e.g.,
username + password), and the authorization (“access”) controls
available to users tend to be quite coarse and not very granular. For
large organizations, this coarse authorization presents significant
security concerns unto itself. Often, the only authorization levels
cloud vendors provide are administrator authorization (i.e., the owner
of the account itself) and user authorization (i.e., all other
authorized users)—with no levels in between (e.g., business unit
administrators, who are authorized to approve access for their own
business unit personnel). Again, these access control issues are not
unique to CSPs, and we discuss them in much greater detail in the
following chapter.
What is definitely relevant to this section, however, is the
second potential concern: how is the data that is stored in the cloud
actually protected? For all practical purposes, protection of data
stored in the cloud involves the use of encryption.
Note:
There has been some discussion in recent years about
alternative data protection techniques; for example, in connection
with the Data Accountability and Trust Act, reported in May 2006.
These alternative techniques included indexing, masking, redaction,
and truncation. However, there are no accepted standards for
indexing, masking, redaction, or truncation—or any other data
protection technique. The only data protection technique for which
there are recognized standards is encryption, such as the NIST
Federal Information Processing Standards (FIPS); see http://www.itl.nist.gov/fipspubs/.
So, is a customer’s data actually encrypted when it is stored in
the cloud? And if so, with what encryption algorithm, and with what
key strength? It depends, and specifically, it depends on which CSP
you are using. For example, EMC’s MozyEnterprise
does encrypt a customer’s data. However, AWS S3 does not encrypt a
customer’s data. Customers are able to encrypt their own data
themselves prior to uploading, but S3 does not provide
encryption.
If a CSP does encrypt a customer’s data, the next consideration
concerns what encryption algorithm it uses. Not all encryption
algorithms are created equal. Cryptographically, many algorithms
provide insufficient security. Only algorithms that have been publicly
vetted by a formal standards body (e.g., NIST) or at least informally
by the cryptographic community should be used. Any algorithm that is
proprietary should absolutely be avoided. Note that we are talking
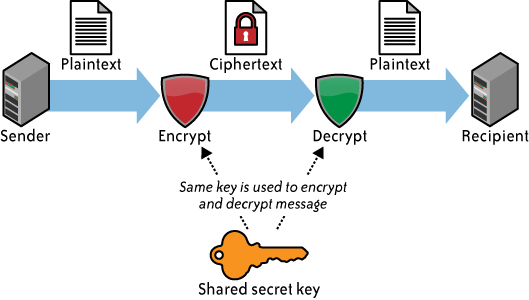
about symmetric encryption algorithms here. Symmetric
encryption (see Figure 1) involves the
use of a single secret key for both the encryption and decryption of
data. Only symmetric encryption has the speed and computational
efficiency to handle encryption of large volumes of data. It would be
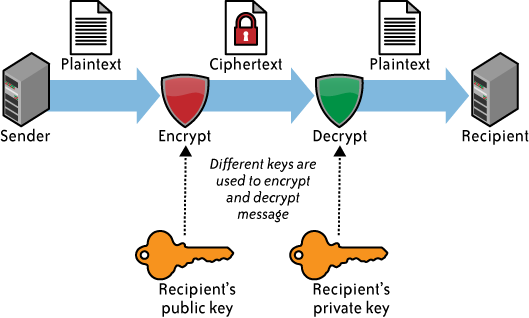
highly unusual to use an asymmetric algorithm for this encryption use
case. (See Figure 2.)
Although the example in Figure 1
is related to email, the same concept (i.e., a single shared, secret
key) is used in data storage encryption.
Although the example in Figure 2
is related to email, the same concept (i.e., a public key and a
private key) is not used in data storage
encryption.
The next consideration for you is what key length is used. With
symmetric encryption, the longer the key length (i.e., the greater
number of bits in the key), the stronger the encryption. Although long
key lengths provide more protection, they are also more
computationally intensive, and may strain the capabilities of computer
processors. What can be said is that key lengths should be a minimum
of 112 bits for Triple DES (Data Encryption Standard) and 128-bits for
AES (Advanced Encryption Standard)—both NIST-approved algorithms. For further information on key
lengths, see NIST’s “Special Publication 800-57, Recommendation for
Key Management—Part 1: General (Revised),” dated March 2007, at http://csrc.nist.gov/publications/nistpubs/800-57/sp800-57-Part1-revised2_Mar08-2007.pdf.
Another confidentiality consideration for encryption is
key management. How are the encryption keys that are
used going to be managed—and by whom? Are you going to manage your own
keys? Hopefully, the answer is yes, and hopefully you have the
expertise to manage your own keys. It is not recommended that you
entrust a cloud provider to manage your keys—at least not the same provider that
is handling your data. This means additional resources and
capabilities are necessary. That being said, proper key management is
a complex and difficult task. At a minimum, a customer should consult
all three parts of NIST’s 800-57, “Recommendation for Key
Management”:
Because key management is complex and difficult for a single
customer, it is even more complex and difficult for CSPs to try to
properly manage multiple customers’ keys. For that reason, several
CSPs do not do a good job of managing customers’ keys. For example, it
is common for a provider to encrypt all of a customer’s data with a
single key. Even worse, we are aware of one cloud storage provider
that uses a single encryption key for all of its customers! The
Organization for the Advancement of Structured Information Standards
(OASIS) Key Management Interoperability Protocol
(KMIP) is trying to address such issues; see http://www.oasis-open.org/committees/tc_home.php?wg_abbrev=kmip.
3.1.2. Integrity
In addition to the confidentiality of your data, you also need to worry
about the integrity of your data. Confidentiality does not imply
integrity; data can be encrypted for confidentiality purposes, and yet
you might not have a way to verify the integrity of that data.
Encryption alone is sufficient for confidentiality, but integrity also
requires the use of message authentication codes (MACs). The simplest way to use MACs on encrypted data is to
use a block symmetric algorithm (as opposed to a streaming symmetric
algorithm) in cipher block chaining (CBC) mode, and to include a one-way hash function. This is
not for the cryptographically uninitiated—and it is one reason why
effective key management is difficult. At the very least, cloud
customers should be asking providers about these matters. Not only is
this important for the integrity of a customer’s data, but it will
also serve to provide insight on how sophisticated a provider’s
security program is—or is not. Remember, however, that not all
providers encrypt customer data, especially for PaaS and SaaS services.
Another aspect of data integrity is important, especially with
bulk storage using IaaS. Once a customer has several gigabytes (or more) of
its data up in the cloud for storage, how does the customer check on
the integrity of the data stored there? There are IaaS transfer costs
associated with moving data into and back down from the
cloud, as well as network utilization (bandwidth)
considerations for the customer’s own network. What a customer really
wants to do is to validate the integrity of its data while that data
remains in the cloud—without having to download and reupload that
data.
This task is even more difficult because it must be done in the
cloud without explicit knowledge of the whole data set. Customers
generally do not know on which physical machines their data is stored,
or where those systems are located. Additionally, that data set is
probably dynamic and changing frequently. Those frequent changes
obviate the effectiveness of traditional integrity insurance
techniques.
What is needed instead is a proof of retrievability—that is, a
mathematical way to verify the integrity of the data as it is dynamically stored in the
cloud.
3.1.3. Availability
Assuming that a customer’s data has maintained its confidentiality and integrity,
you must also be concerned about the availability of your data. There
are currently three major threats in this regard—none of which are new
to computing, but all of which take on increased importance in cloud
computing because of increased risk.
The second threat to availability is the CSP’s own availability.
No CSPs offer the sought-after “five 9s” (i.e., 99.999%) of uptime. A customer would
be lucky to get “three 9s” of uptime. As Table 1 shows, there is a considerable
difference between five 9s and three 9s.
Table 1. Percentage of uptime
| | Total downtime (HH:MM:SS) |
|---|
| Availability | Per
day | Per
month | Per
year |
|---|
| 99.999% | 00:00:00.4 | 00:00:26 | 00:05:15 |
| 99.99% | 00:00:08 | 00:04:22 | 00:52:35 |
| 99.9% | 00:01:26 | 00:43:49 | 08:45:56 |
| 99% | 00:14:23 | 07:18:17 | 87:39:29 |
A number of high-profile cloud provider outages have occurred.
For example, Amazon’s S3 suffered a 2.5-hour outage in February 2008 and an
eight-hour outage in July 2008. AWS is one of the more mature cloud providers, so
imagine the difficulties that other, smaller or less mature cloud
providers are having. These Amazon outages were all the more apparent
because of the relatively large number of customers that the S3
service supports—and whom are highly (if not totally) reliant on S3’s
availability for their own operations.
In addition to service outages, in some cases data stored in the
cloud has actually been lost. For example, in March 2009, “cloud-based
storage service provider Carbonite Inc. filed a lawsuit charging that faulty
equipment from two hardware providers caused backup failures that
resulted in the company losing data for 7,500 customers two years
ago.”
A larger question for cloud customers to consider is whether
cloud storage providers will even be in business in the future. In
February 2009, cloud provider Coghead suddenly shut down, giving its customers fewer
than 90 days (nine weeks) to get their data off its servers—or lose it
altogether.
Finally, prospective cloud storage customers must be certain to
ascertain just what services their provider is actually offering.
Cloud storage does not mean the stored data is actually backed up.
Some cloud storage providers do back up customer data, in addition to
providing storage. However, many cloud storage providers do not back
up customer data, or do so only as an additional service for an
additional cost. For example, “data stored in Amazon S3, Amazon
SimpleDB, or Amazon Elastic Block Store is redundantly stored in multiple physical locations as
a normal part of those services and at no additional charge.” However,
“data that is maintained within running instances on Amazon EC2, or
within Amazon S3 and Amazon SimpleDB, is all customer data and
therefore AWS does not perform backups.” For availability, this is a seemingly simple yet
critical question that customers should be asking of cloud storage
providers.
All three of these considerations (confidentiality, integrity,
and availability) should be encapsulated in a CSP’s service-level
agreement (SLA) to its customers. However, at this time, CSP SLAs
are extremely weak—in fact, for all practical purposes, they are
essentially worthless. Even where a CSP appears to have at least a
partially sufficient SLA, how that SLA actually gets measured is
problematic. For all of these reasons, data security considerations
and how data is actually stored in the cloud should merit considerable
attention by customers.